Assistenti AI verticali: architettura, memoria e tool calling
C'è una differenza sostanziale tra un chatbot e un assistente AI verticale. Un chatbot risponde. Un assistente conosce il dominio, ricorda il contesto, usa strumenti concreti e si comporta come un consulente che ha già letto il fascicolo del cliente prima della riunione.
LD Chat v3.2 è il framework che Livedata usa per costruire assistenti di questo secondo tipo. Questo articolo spiega come funziona, perché abbiamo fatto certe scelte architetturali, e cosa significa concretamente "assistente AI verticale" quando si esce dalla teoria e si entra nella produzione.
Il problema dei chatbot generici
La prima generazione di assistenti AI per siti web seguiva uno schema semplice: widget di chat → API OpenAI → risposta generica. Funzionava abbastanza bene per le FAQ, meno bene per tutto il resto.
I limiti erano strutturali. Il modello non sapeva nulla del dominio specifico — prezzi reali, camere disponibili, prodotti a catalogo, procedure aziendali. Ogni risposta era una ricostruzione probabilistica basata su dati di addestramento generali. Il modello "inventava" prezzi plausibili, citava politiche inesistenti, suggeriva soluzioni che non corrispondevano all'offerta reale del cliente.Il secondo limite era la memoria. Ogni messaggio partiva da zero. L'utente che scriveva "quello che mi hai detto prima" riceveva una risposta che non teneva conto di nulla di quello che era stato detto prima, perché non c'era nessun "prima" nel contesto del modello.
Il terzo limite era l'interfaccia. Il testo puro non basta per comunicare un catalogo prodotti, un confronto tra opzioni, una timeline di progetto. Le informazioni strutturate richiedono UI strutturata — card, tabelle, chip — non paragrafi.
LD Chat nasce per risolvere questi tre problemi in modo sistematico.
Assistenti AI verticali: architettura, memoria e tool calling
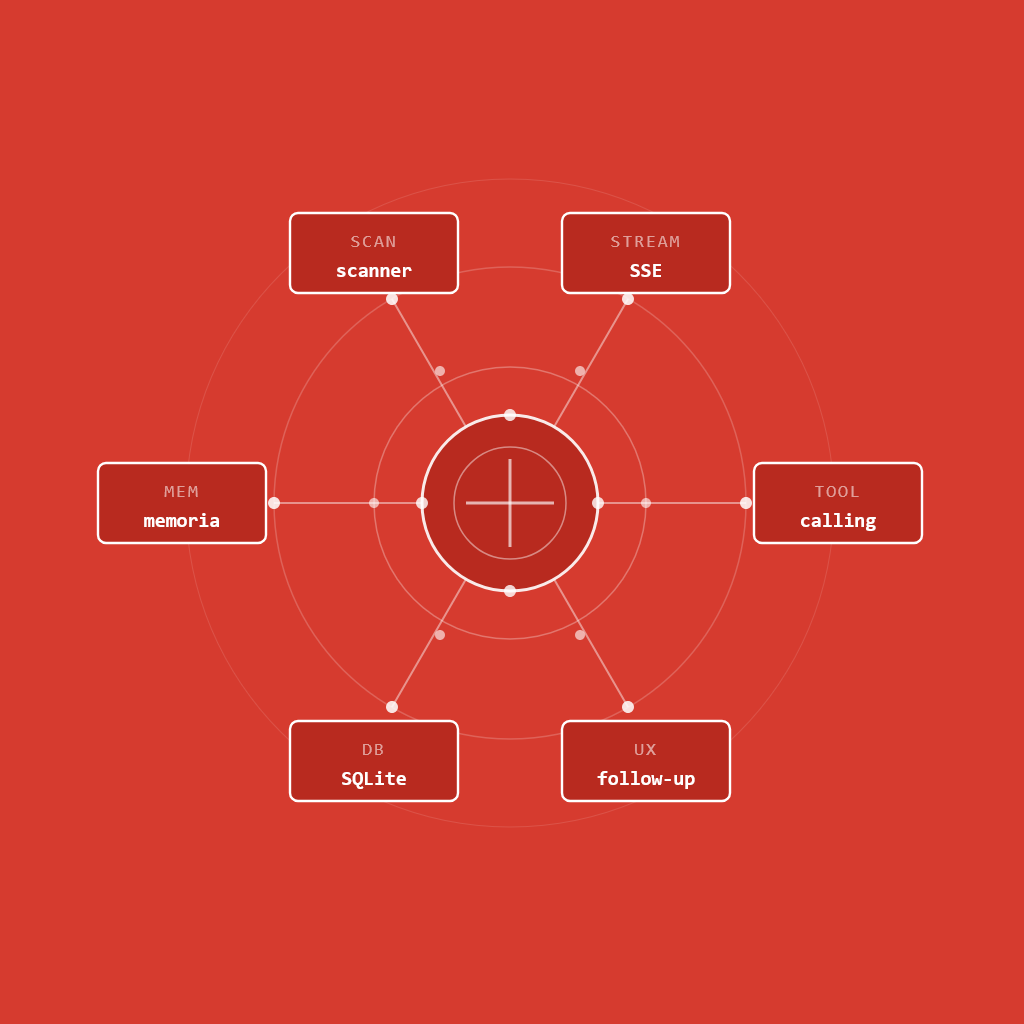
L'architettura: sette livelli integrati
Livello 1 — Tool calling al posto dei token inline
La prima versione di LD Chat usava un pattern home-made: il modello generava token speciali nel testo ([[service:custom-website]]) che il frontend intercettava con espressioni regolari e convertiva in componenti Vue. Funzionava, ma era fragile. Se il modello alterava leggermente il formato del token — cosa che succedeva — il parsing silenziosamente falliva.
Con LD Chat v3.0 siamo passati al tool calling nativo di OpenAI. Il modello non "scrive" token nel testo — chiama funzioni tipizzate con parametri validati da JSON Schema. Il server intercetta la chiamata, esegue la funzione, restituisce i dati strutturati al modello, e il modello riprende lo stream con la risposta finale.
Utente: "Quanto costa un sito web custom?"
[Modello decide di chiamare show_service_card]
→ server: executeToolCall('show_service_card', { service_id: 'custom-website' })
→ SSE event 'tool_call' → frontend mostra placeholder
→ SSE event 'tool_result' → frontend renderizza la card
[Modello riprende lo stream]
→ "Per il tuo progetto, questa soluzione include..."Il risultato è uno stream fluido senza interruzioni visibili, con card che appaiono inline nel flusso della conversazione. Zero parsing regex nel frontend. Dati tipizzati e validati lato server.
I tool disponibili in v3.2 sono sette: show_service_card, show_comparison_card, show_checklist_card, show_stats_card, show_timeline_card, scan_website e suggest_followups. Aggiungerne uno nuovo richiede tre punti — definizione JSON Schema, case nell'executor, componente Vue — senza toccare il server principale.
Livello 2 — Il loop agentico
Un assistente che può chiamare un solo tool per risposta è limitato. Un assistente che può eseguire sequenze — scansiona un sito, poi genera i follow-up contestuali — è qualcosa di diverso.
LD Chat implementa un loop agentico nel handler della richiesta:
while (loopCount < MAX_LOOPS) {
stream OpenAI
if (finish_reason === 'tool_calls') {
esegui tool
aggiungi tool_result alla conversazione
continua loop (seconda call)
} else {
break (risposta completata)
}
}Il loop ha un safety cap (MAX_LOOPS = 4) per evitare spirali infinite. Nella pratica, la sequenza più lunga è: scan website → risposta → suggest followups, tre giri con un costo marginale in latenza che l'utente non percepisce perché lo stream è già attivo.
L'unico tool che può affiancare un altro nella stessa risposta è suggest_followups, esplicitamente dichiarato come eccezione nel system prompt. Tutti gli altri: uno per risposta.
Livello 3 — La memoria a tre livelli
Questo è il punto dove la maggior parte degli assistenti AI cade.
RAM (veloce, effimera): ogni sessione attiva vive in un Map<sessionId, SessionEntry> in-memory. Il client non invia più l'intera history ad ogni richiesta — il server mantiene il buffer. Questo elimina il rischio di history manipolate lato client e riduce il payload di ogni richiesta.
Compressione asincrona: quando una sessione supera i 10 turni, una call non-bloccante a gpt-4o-mini con temperatura 0.3 produce un summary compresso dei turni precedenti. Il buffer si svuota, il summary resta. Lo stream corrente non viene mai bloccato — la compressione avviene dopo che il server ha già risposto all'utente.
[SessionStore] Compressing session ld_906e3580: 20 msgs → summary
[SessionStore] Session ld_906e3580 compressed + persisted.
Summary: "L'utente ha chiesto informazioni sui progetti Livedata..."SQLite (duratura, cross-session): il summary compresso viene scritto su disco. Quando un utente torna — anche dopo giorni, anche dopo un restart del server — il summary viene caricato da SQLite e iniettato nel system prompt. L'assistente riprende il filo senza che l'utente debba ripetere nulla.
Il TTL è configurabile: 90 giorni per i log delle conversazioni, 180 giorni per i profili utente e i summary. Tutto via variabili d'ambiente, senza modifiche al codice.
Livello 4 — Il website scanner
Uno degli use case più concreti per un assistente B2B è questo: l'utente condivide l'URL del proprio sito, l'assistente lo analizza e risponde con osservazioni specifiche invece di fare domande generiche.
websiteScanner.js fa fetch della pagina (timeout 8s, max 500KB), estrae titolo, meta description, struttura heading H1/H2, canonical, e rileva lo stack tecnologico tramite signature tecniche nel codice HTML:
- CMS: WordPress, ProcessWire, Shopify, Webflow, Ghost e altri
- Framework JS: Next.js, Nuxt, Vue, React, Angular, Svelte, Astro
- Analytics: Google Analytics, GTM, Plausible, Hotjar, Clarity
- Hosting/CDN: Vercel, Netlify, AWS, Aruba e altri
Una nota tecnica importante: le signature di rilevamento usano sempre marker tecnici univoci, mai la semplice presenza del nome nel testo. Il rilevamento di Astro, per esempio, controlla data-astro-*, /_astro/ nei path, o l'event listener astro:page-load — non la parola "astro" nel contenuto della pagina, che darebbe falsi positivi.
La sicurezza è implementata a strati: allowlist di TLD accettati, blocklist di 30+ domini di servizi comuni, blocco di indirizzi privati (RFC1918, loopback, link-local, IP nudi), rate limiting per sessione (max 3 scan) e globale (max 30/minuto).
Livello 5 — Follow-up dinamici contestuali
I follow-up tradizionali sono hardcoded: "vuoi saperne di più?", "hai altre domande?". Inutili.
In LD Chat v3.2 i follow-up sono generati dal modello alla fine di ogni risposta tramite il tool suggest_followups. Il modello produce 2-3 domande specifiche al contesto della conversazione, ciascuna con un tipo semantico: deepen (approfondimento tecnico), scope (chiarimento progetto), action (passo successivo concreto), compare (confronto tra opzioni).
Il frontend renderizza i chip con un punto colorato per tipo — viola per approfondimento, verde per scope, corallo per azione, ambra per confronto — che fornisce un segnale visivo immediato sull'intenzione della domanda senza aggiungere rumore testuale.
json
{
"items": [
{ "text": "Come funziona ProcessWire rispetto a WordPress?", "type": "deepen" },
{ "text": "Ho un hotel — cosa cambia rispetto a un sito standard?", "type": "scope" },
{ "text": "Come si richiede un preventivo?", "type": "action" }
]
}
Livello 6 — Il sistema prompt disciplinato
Il prompt di LD Chat ha una struttura rigida: identità → percorso del cliente → formato (non negoziabile) → tool → ritmo conversazionale → stile → riferimenti reali → fuori scope → knowledge base.
Il blocco formato viene prima di tutto il resto, una posizione ad alta priorità nel context window. Include divieti espliciti formulati in modo imperativo — "PROIBITO in ogni risposta, senza eccezioni" — con esempi negativi concreti:
ESEMPIO SBAGLIATO (non farlo MAI):
"Osservazioni: • CMS: ProcessWire • SEO: meta da migliorare
- Stack: moderno. Fammi sapere se vuoi approfondire."
ESEMPIO CORRETTO:
"ProcessWire custom — buon segno per le performance. La meta
description è troppo generica per il SEO. Cosa ti ha spinto
a valutare il sito adesso?"Su gpt-4o-mini, gli esempi negativi espliciti funzionano meglio dei soli divieti astratti. Il modello deve vedere cosa non fare, non solo sentirsi dire di non farlo.
Livello 7 — Analytics e osservabilità
Un assistente in produzione genera dati. LD Chat v3.2 traccia ogni conversazione su SQLite: fonte della risposta (AI o fallback deterministico), servizi menzionati, segnali di conversione a tre livelli (interesse → richiesta contatto → preventivo), lingua dell'utente, distribuzione oraria.
La dashboard analytics costruita su questi dati offre otto viste: volume conversazioni nel tempo (AI vs fallback), heatmap oraria per identificare i picchi di traffico, funnel di conversione, word cloud delle domande più frequenti, matrice profilo × intento degli utenti, flusso conversazionale Sankey, distribuzione lingue, e un live feed in tempo reale delle conversazioni attive. I dati sono esportabili in CSV per analisi esterne.
Per i clienti che ricevono l'assistente come servizio, la dashboard diventa lo strumento con cui misurano il ROI — quante conversazioni gestite, quanti lead qualificati generati, quali servizi vengono cercati più spesso.
La scelta del modello: perché gpt-4o-mini
Una domanda legittima è: perché non GPT-4o o Claude Opus per un assistente professionale?
La risposta è pragmatica. Per assistenti verticali con knowledge base definita, la qualità della risposta dipende principalmente da tre fattori: precisione del system prompt, qualità della knowledge base RAG, e struttura del tool calling. Il modello è importante, ma non è il fattore dominante.
gpt-4o-mini ha latenza bassa — critico per lo streaming SSE dove ogni centesimo di secondo si percepisce. Ha un costo token molto inferiore — importante quando si gestiscono conversazioni lunghe con compressione asincrona. E supporta tool calling nativo con la stessa API di GPT-4o.
Usiamo modelli più potenti per task specifici: la compressione dei summary usa gpt-4o-mini a temperatura 0.3 (task di sintesi, non di creatività). Il pattern Planner+Executor, in roadmap, userebbe GPT-4o per la pianificazione e gpt-4o-mini per l'esecuzione.
Il multilingua come opzione nativa
LD Chat è progettato per supportare il multilingua come opzione configurabile, non come retrofit. L'architettura adotta il principio detect-once, propagate-always: la lingua viene rilevata una sola volta all'apertura della chat (parametro URL → localStorage → navigator.language → default italiano) e propagata a ogni livello del sistema.
Questo significa che il system prompt riceve un blocco lingua esplicito nella lingua dell'utente, i fallback deterministici restituiscono risposte nella lingua corretta, il tool suggest_followups genera le domande di follow-up nella lingua dell'utente, il Text-to-Speech usa la voce appropriata, e le stringhe UI (placeholder, label, messaggi di errore) sono localizzate tramite un oggetto i18n centralizzato.
SSE: perché non WebSocket
Una scelta tecnica che vale la spiegazione è il protocollo di streaming. LD Chat usa Server-Sent Events (SSE) invece di WebSocket.
SSE è unidirezionale (server → client), più semplice da implementare, compatibile con qualsiasi reverse proxy senza configurazioni speciali (bastano proxy_buffering off e X-Accel-Buffering: no su Nginx), e non richiede handshake — la connessione è una normale HTTP con Content-Type: text/event-stream.
Per un assistente conversazionale il flusso è quasi sempre unidirezionale: il client invia un messaggio (POST standard), il server risponde in streaming (SSE). WebSocket avrebbe senso per applicazioni collaborative in tempo reale — non per questo use case.
Il canale SSE trasporta eventi tipizzati: source (indica l'origine della risposta), delta (chunk di testo in streaming), tool_call (il modello sta chiamando uno strumento), tool_result (dati strutturati pronti per il rendering), followups (chip dinamici), services (per analytics), done (fine stream), error (con flag recoverable).
Cosa abbiamo imparato
Lavorando su LD Chat abbiamo verificato due comportamenti del modello che la letteratura sul prompt engineering descrive ma che è diverso sperimentare in produzione. Il primo: la posizione delle istruzioni nel context window è rilevante. Le regole critiche messe in testa al prompt — prima della knowledge base, prima dei riferimenti — tengono meglio su conversazioni lunghe rispetto alle stesse regole messe in fondo. Il secondo: gli esempi negativi espliciti funzionano sistematicamente meglio dei divieti astratti. Scrivere "PROIBITO usare liste puntate" produce risultati peggiori rispetto a mostrare, fianco a fianco, la risposta sbagliata con bullet e quella corretta in prosa. Il modello non sta seguendo una regola — sta imitando un pattern. Dargli il pattern sbagliato da non imitare è più efficace che descrivere il divieto in astratto.
La fluidità percepita dipende dall'architettura SSE. Prima del tool calling nativo, il frontend doveva intercettare token parziali durante lo streaming e nasconderli fino al parsing completo. Questo causava microinterruzioni visibili. Con il tool calling, il testo arriva pulito e il frontend non deve fare nessuna trasformazione mid-stream.
Il rate limiting deve essere a due livelli. IP e sessione. Un rate limit solo per IP è aggirabile con proxy. Un rate limit solo per sessione è aggirabile con sessionId multipli. Entrambi insieme coprono i casi d'uso reali.
La memoria è la feature che gli utenti notano di meno e apprezzano di più. Nessun utente dirà "ottima compressione asincrona". Ma tutti notano quando un assistente li accoglie con "la volta scorsa mi hai parlato di un sito per il tuo hotel — siamo ancora su quello scope?" dopo una settimana di assenza.
Roadmap
Tre funzionalità che completerebbero il sistema commercialmente:
send_inquiry_email — il cerchio commerciale non si chiude senza un momento di conversione. Il tool raccoglie nome, email e scope del progetto dalla conversazione e invia un brief preformattato. Nessun booking engine, nessuna integrazione con CRM — solo SMTP e un'email strutturata che arriva già qualificata.
Proactive nudge — l'assistente che inizia lui. Trigger comportamentali (scroll depth, tempo pagina, exit intent) che aprono la chat con un messaggio contestuale. Con la memoria cross-session attiva, il messaggio può essere personalizzato: "Bentornato — hai avuto modo di valutare la proposta per il sito dell'hotel?"
Planner + Executor — per query complesse che richiedono pianificazione. Una prima call rapida (GPT-4o) pianifica quali strumenti usare e in che ordine. Una seconda call (gpt-4o-mini) esegue il piano in streaming. La qualità della risposta migliora su query multi-step senza aumentare la latenza percepita.
Conclusione
Un assistente AI verticale professionale non è un chatbot con un system prompt più lungo. È un sistema in cui ogni livello — tool calling, memoria, streaming, sicurezza, prompt engineering — è progettato per lavorare in modo coerente con gli altri. Togline uno e gli altri perdono senso: la memoria senza il tool calling è un archivio muto, il tool calling senza un prompt disciplinato è una macchina che decide a caso quando agire.
LD Chat è il risultato di un percorso iterativo, fatto di conversazioni reali in produzione e di scelte tecniche deliberate più che di feature aggiunte per inerzia. Non è un sistema finito — nessun software lo è — ma è abbastanza solido da fare da base per assistenti molto diversi tra loro: un consulente digitale B2B, il concierge di un hotel, l'assistente di una marina. Cambiano il dominio e i dati; l'architettura resta.
Se stai valutando un assistente AI per il tuo sito o per la tua struttura, la domanda giusta non è "quale chatbot uso", ma "di cosa ha bisogno davvero chi mi scrive, e cosa deve sapere e saper fare un assistente per rispondere a quel bisogno". Le risposte determinano l'architettura. L'architettura determina il prodotto.
Livedata — livedata.it Sviluppo web custom, assistenti AI verticali, dashboard data viz Richiedi un preventivo · info@livedata.it